Данное методическое пособие предназначено для студентов третьего курса экономических специальностей. В документе подробно описан процесс выполнения лабораторных работ по эконометрике с использованием MS Excel. Рассматриваются темы: первичная обработка статистических данных, группировка данных, построение гистограмм и многоугольников распределения, анализ вида эмпирического распределения, а также расчет интервальных оценок параметров нормального распределения.
Содержание
Лабораторные работы по эконометрике
Для студентов третьего курса экономических специальностей. Чита, 2013. Автор: Носальская Татьяна Эдуардовна.
Лабораторная работа №1. Часть 1. Первичная обработка данных
- Создаём рабочий файл «Элементы математической статистики.xlsx» или «Элементы математической статистики.xls» (для MS Excel 1997-2003).
- «Лист1» переименовываем в «Выборка».
- Генеральной совокупностью называют совокупность всех мысленно возможных объектов данного вида, над которыми проводятся наблюдения с целью получения конкретных значений случайной величины, или совокупность результатов всех мыслимых наблюдений, проводимых в неизменных условиях над одной из случайных величин, связанных с данным видом объектов. Часто генеральная совокупность содержит конечное число объектов. Однако если это число достаточно велико, то иногда в целях упрощения вычислений допускают, что генеральная совокупность состоит из бесконечного множества объектов.
- Выборкой называется множество случаев (испытуемых, объектов, событий, образцов), с помощью определённой процедуры выбранных из генеральной совокупности для участия в исследовании.
- Объемом выборки называют число объектов, содержащихся в ней.
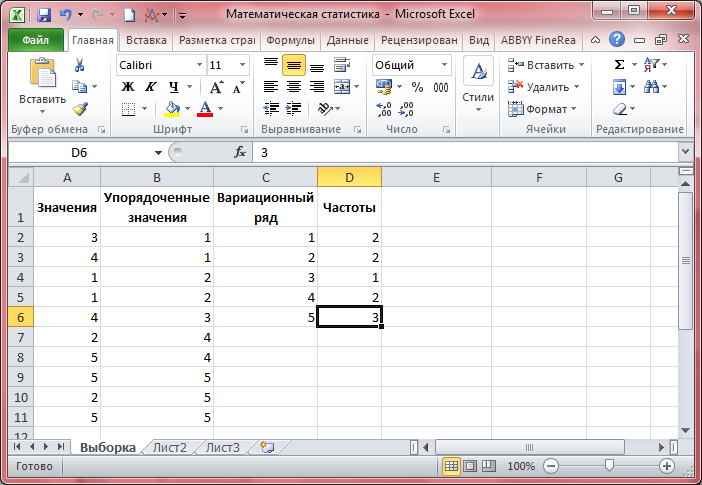
- Даны значения, представляющие выборку из генеральной совокупности, которая подчинена некоторому непрерывному распределению. Запишите их в столбец A рабочего листа, внеся в ячейку A1 заголовок «Значения».
Варианты заданий
Ниже представлены наборы данных для 24 вариантов:
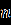
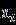
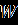
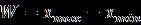

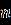
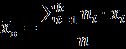
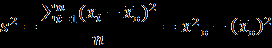

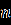
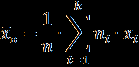
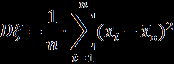
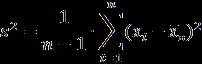
Продолжение обработки данных
- Размахом выборки называют разность между минимальным и максимальным значениями её элементов. Определите/вычислите и запишите в нижние ячейки В103 и B104 объём и размах выборки, соответственно. В ячейках A103 и A104 подпишите наименования «Объём», «Размах».
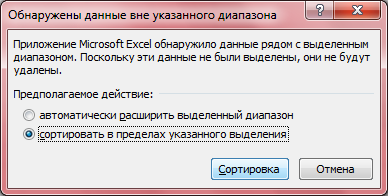
- Вариационным рядом выборки называют упорядоченные по возрастанию выборочные значения. Столбец B озаглавьте «Упорядоченные значения». Скопируйте в него все значения столбца A. Выделите все скопированные значения в столбце B, после чего вызовите правой кнопкой мыши контекстное меню и выберите Сортировка -> Сортировка от минимального к максимальному -> Сортировка в пределах указанного выделения -> Сортировка.
- Столбец С озаглавьте «Вариационный ряд». Скопируйте в него по порядку уникальные значения столбца B.
- Столбец D озаглавьте «Частоты». Здесь напротив каждого значения вариационного ряда запишите частоту его появления, то есть количество одинаковых значений.
Вычисления в Excel
- Столбец E озаглавьте «Относительные частоты». Относительные частоты можно вычислить по формуле w = n_i / n, где n – объём выборки. Для этого в ячейку E2 записываем формулу
=D2/$B$103. Растяните эту формулу вниз до ячейки E101. - Столбец F озаглавьте «Накопленные частоты». В ячейку F2 запишите формулу
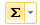
=E2, а в ячейку F3 формулу=E3+F2. Растяните эту формулу вниз до ячейки F101. - Вычислите выборочное среднее. Озаглавьте столбец G «nx». В ячейке G2 запишите формулу
=E2*C2. Растяните вниз до G101 и нажмите кнопку суммирования. - Вычислите выборочную дисперсию. Озаглавьте столбец H «x^2». В ячейке H2 запишите
=С^2. Растяните вниз до H101. - Столбец I озаглавьте «nx^2». В ячейке I2 запишите
=E2*H2. Растяните вниз до I101 и просуммируйте. - Вычислите среднеквадратическое отклонение как корень из дисперсии.
Группировка данных
- Открываем рабочий файл, «Лист2» переименовываем в «Группированные данные».
- Скопируйте в столбец A вариационный ряд из ЛР №5 вместе с заголовком.
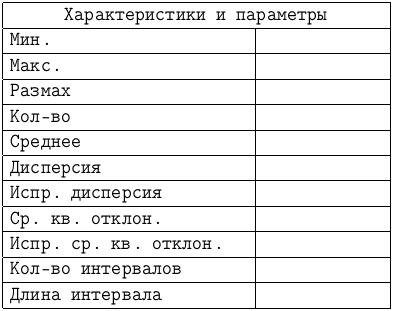
- Блок ячеек B1:C12 оформите для внесения статистических показателей.
- Найдите минимальный элемент (
=МИН(A2:A101)), максимальный (=МАКС(A2:A101)), размах, объём (=СЧЁТ(A2:A101)), среднее (=СРЗНАЧ(A2:A101)), дисперсию (=ДИСПР(A2:A101)), исправленную дисперсию (=ДИСП(A2:A101)), СКО (=СТАНДОТКЛОНП(A2:A101)) и исправленное СКО (=СТАНДОТКЛОН(A2:A101)). - Сгруппируйте данные. Число интервалов вычисляется по формуле
=1+ОКРУГЛВНИЗ(LOG(С5;2);0).
Построение гистограмм
- Блок ячеек D1:K8 оформите для интервалов.
- В ячейки E2:E8 поместите значения левых концов интервалов, в F2:F8 — правых.
- В ячейку G2 запишите
=(E2+F2)/2. - Выделите диапазон H2:H8, выберите функцию «Частота» (Статистические). В поле Массив_данных внесите A2:A101, в Массив_интервалов – F2:F7. Нажмите Ctrl+Shift+Enter.
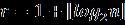
- Вычислите относительные частоты, накопленные частоты и высоты столбцов.
- Постройте многоугольник распределения и гистограмму.
Часть 2. Анализ вида эмпирического распределения
- «Лист3» переименуйте в «Распределение».
- Вычислите среднее, СКО, медиану, эксцесс, асимметрию и моду.
- Нормируйте данные:
=(A2-$B$2)/$B$3. - Вычислите относительные частоты (
=1/$A$102) и накопленные относительные частоты. - Вычислите квантили стандартного нормального распределения:
=НОРМОБР(E2;0;1). - Постройте диаграмму (точечную с прямыми отрезками) для значений столбцов C и F.
- При необходимости добавьте линию тренда для проверки нормальности распределения.
Интервальные оценки параметров нормального распределения
- Создаём чистый лист «Оценки».
- Создайте таблицу для параметров: объём выборки, степени свободы, корень из n, уровень значимости, выборочное среднее, s0, s0^2, Sigma, Z, T, Хи лев., Хи прав.
- Оценка математического ожидания: используйте
=ДОВЕРИТ.НОРМ(B6;B12;B1)для известного СКО. - Для неизвестного СКО используйте критическую точку распределения Стьюдента:
=СТЬЮДРАСПОБР(B6;B2). - Оценка дисперсии: используйте критические точки распределения Пирсона
=ХИ2ОБР(B7;B2)и=ХИ2ОБР(B8;B2).