Данное методическое пособие содержит пошаговые инструкции по выполнению лабораторных работ по эконометрике для студентов третьего курса экономических специальностей. В материале подробно описаны процессы первичной обработки данных, группировки выборки, построения гистограмм и многоугольников распределения, а также методы анализа эмпирического распределения и расчета интервальных оценок параметров нормального распределения с использованием инструментов MS Excel.
Содержание
Лабораторные работы по эконометрике
Для студентов третьего курса экономических специальностей. Чита, 2013. Автор: Носальская Татьяна Эдуардовна.
Лабораторная работа №1. Часть 1. Первичная обработка данных
- Создаём рабочий файл «Элементы математической статистики.xlsx» или «Элементы математической статистики.xls» (для MS Excel 1997-2003).
- «Лист1» переименовываем в «Выборка».
- Генеральной совокупностью называют совокупность всех мысленно возможных объектов данного вида, над которыми проводятся наблюдения с целью получения конкретных значений случайной величины, или совокупность результатов всех мыслимых наблюдений, проводимых в неизменных условиях над одной из случайных величин, связанных с данным видом объектов. Часто генеральная совокупность содержит конечное число объектов. Однако если это число достаточно велико, то иногда в целях упрощения вычислений допускают, что генеральная совокупность состоит из бесконечного множества объектов. Такое допущение оправдывается тем, что увеличение объема генеральной совокупности (достаточно большого объема) практически не сказывается на результатах обработки данных выборки.
- Выборкой называется множество случаев (испытуемых, объектов, событий, образцов), с помощью определённой процедуры выбранных из генеральной совокупности для участия в исследовании.
- Объемом выборки называют число объектов, содержащихся в ней.
- Даны значения, представляющие выборку из генеральной совокупности, которая подчинена некоторому непрерывному распределению. Запишите их в столбец A рабочего листа, внеся в ячейку A1 заголовок «Значения».
Варианты заданий
Ниже представлены данные для 24 вариантов (Вариант 1 – Вариант 24).
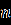
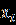
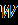
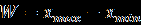
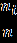
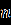
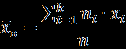
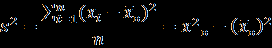

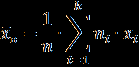

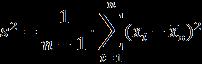
Продолжение обработки данных
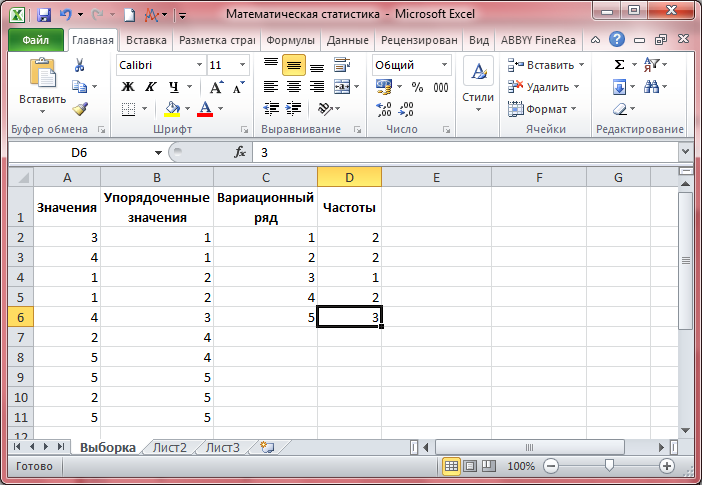
- Размахом выборки называют разность между минимальным и максимальным значениями её элементов, т.е. R = x_max — x_min. Определите/вычислите и запишите в нижние ячейки В103 и B104 объём и размах выборки, соответственно. В ячейках A103 и A104 подпишите наименования «Объём», «Размах».
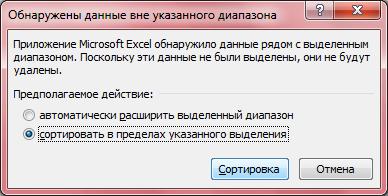
- Вариационным рядом выборки называют упорядоченные по возрастанию выборочные значения. Столбец B озаглавьте «Упорядоченные значения». Скопируйте в него все значения столбца A. Выделите все скопированные значения в столбце B, после чего вызовите правой кнопкой мыши контекстное меню и выберите Сортировка -> Сортировка от минимального к максимальному -> Сортировка в пределах указанного выделения -> Сортировка.
- Столбец С озаглавьте «Вариационный ряд». Скопируйте в него по порядку уникальные значения столбца B, т.е. каждое значение теперь будет представлено ровно по одному разу.
- Столбец D озаглавьте «Частоты». Здесь напротив каждого значения вариационного ряда запишите частоту его появления n_i, то есть количество одинаковых значений, или повторяемость значений.
Вычисления в Excel
- Столбец E озаглавьте «Относительные частоты». Относительные частоты можно вычислить по формуле w_i = n_i / n, где n – объём выборки. Для этого в ячейку E2 записываем формулу
=D2/$B$103. Растяните эту формулу вниз до ячейки E101. - Столбец F озаглавьте «Накопленные частоты». Вычисляются они следующим образом: первая накопленная частота равна первой относительной частоте. Вторая накопленная частота равна сумме первой накопленной частоты и второй относительной частоты. И так далее. В последней ячейке обязательно должна получиться единица. Для вычисления в ячейку F2 запишите формулу
=E2, а в ячейку F3 формулу=E3+F2. Растяните эту формулу вниз до ячейки F101. - Вычислите выборочное среднее. Для этого озаглавьте столбец G «nx». В ячейке G2 запишите формулу
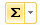
=E2*C2. Растяните эту формулу вниз до ячейки G101. После чего выделите диапазон ячеек G2:G101 и нажмите кнопку суммирования на панели инструментов Редактирование. - Вычислите выборочную дисперсию. Для этого озаглавьте столбец H «x^2». В ячейке H2 запишите формулу
=C2^2. Растяните эту формулу вниз до ячейки H101. - Столбец I озаглавьте «nx^2». В ячейке I2 запишите формулу
=E2*H2. Растяните эту формулу вниз до ячейки I101. После чего вновь просуммируйте полученные в этом столбце значения. - Вычислите среднеквадратическое отклонение как корень из дисперсии.
Группировка данных
- Открываем рабочий файл «Элементы математической статистики.xlsx».
- «Лист2» переименовываем в «Группированные данные».
- Скопируйте в столбец A вариационный ряд из ЛР №5 вместе с заголовком.
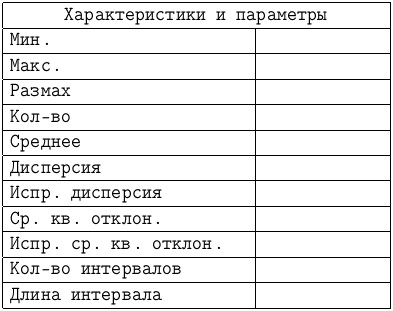
- Блок ячеек B1:C12 оформите для внесения статистических параметров.
- Найдите минимальный элемент. В ячейку С2 поместите формулу
=МИН(A2:A101). - Найдите максимальный элемент. В ячейку С3 поместите формулу
=МАКС(A2:A101). - Найдите размах значений в ячейке C4.
- Найдите объём выборки, поместив в ячейку С5 формулу
=СЧЁТ(A2:A101). - Вычислите выборочное среднее, поместив в ячейку С6 формулу
=СРЗНАЧ(A2:A101). - Вычислите дисперсию, поместив в ячейку С7 формулу
=ДИСПР(A2:A101). - Вычислите исправленную дисперсию, поместив в ячейку С8 формулу
=ДИСП(A2:A101). - Вычислите среднеквадратическое отклонение, пользуясь в ячейке С9 формулой
=СТАНДОТКЛОНП(A2:A101). - Вычислите исправленное среднеквадратическое отклонение, пользуясь в ячейке С10 формулой
=СТАНДОТКЛОН(A2:A101).
Интервалы группировки
- Сгруппируйте данные. Длина интервала — размах выборки.
- Число интервалов определяется по формуле Стерджесса. В ячейку С11 запишите
=1+ОКРУГЛВНИЗ(LOG(С5;2);0). - Длина каждого интервала группировки вычисляется в ячейке С12.
- Блок ячеек D1:K8 оформите для интервалов. В ячейки D1:D8 поместите номера интервалов.
- В ячейки E2:E8 поместите значения левых концов интервалов. В ячейку E2 запишем
=C2, а в ячейку E3=E2+$С$12. - Определите значения правых концов интервалов в ячейках F2:F8. В ячейку F2 запишите
=E2+$С$12. - Запишите в ячейку G2 формулу
=(E2+F2)/2. - Выделите диапазон ячеек H2:H8. Выберите функцию Частота.
В поле Массив_данных внесите A2:A101, в поле Массив_интервалов – F2:F7. Нажмите Ctrl+Shift+Enter.
- Вычислите сумму значений в F9.
- Вычислите относительные частоты в I2:I8:
=H2/$С$5. - Вычислите накопленные относительные частоты в J2:J8.
- Вычислите высоты столбцов диаграммы в K2:K8:
=I2/C$12$. - Постройте многоугольник распределения (Точечная с прямыми отрезками).
- Постройте гистограмму относительных частот.
- Найдите моду и постройте эмпирическую функцию распределения.
Часть 2. Анализ вида эмпирического распределения
- «Лист3» переименуйте в «Распределение».
- Скопируйте данные в A2:A101.
- Вычислите параметры: среднее, несмещённое СКО, медиану, эксцесс, асимметрию и моду (функции
СРЗНАЧ,СТАНДОТКЛОН,МЕДИАНА,ЭКСЦЕСС,СКОС,МОДА). - Нормируйте данные в столбце C:
=(A2-$B$2)/$B$3. - Заполните относительные частоты в D2:D101:
=1/$A$102. - Установите числовой формат с 3 знаками после запятой.
- Вычислите накопленные относительные частоты в E2:E101.
- Вычислите квантили стандартного нормального распределения в F2:F101:
=НОРМОБР(E2;0;1). - Постройте диаграмму (столбцы C и F). Если точки лежат вблизи прямой, добавьте линию тренда (линейная, показать уравнение и достоверность аппроксимации).
Интервальные оценки параметров нормального распределения
- Создаём лист «Оценки».
- Создайте таблицу для параметров: объём выборки, степени свободы, корень из n, уровень значимости, alpha, выборочное среднее, s0, s0^2, Sigma, Z, T, Хи лев., Хи прав.
- Заполните ячейки формулами для расчёта доверительных интервалов.
- Для математического ожидания при известном Sigma используйте
=ДОВЕРИТ.НОРМ(B6;B12;B1). - Для математического ожидания при неизвестном Sigma используйте распределение Стьюдента:
=СТЬЮДРАСПОБР(B6;B2). - Для оценки дисперсии используйте распределение Пирсона:
=ХИ2ОБР(B7;B2)и=ХИ2ОБР(B8;B2).